| | Categorie Articoli | | > Prove | | > Attualitŕ | | > Approfondimenti | | > Interviste | | Altro su HIRC | | > Segnalaci una notizia | | > Advertising | | > Forum |  | | Ultime dal forum | | Visualizza HIRC del | | |
| | Synergistic Processor Element e storage model | Ciascuna delle SPE integrate in un processore Cell č una entitŕ autonoma, nella fattispecie un processore vettoriale capace di eseguire i propri compiti indipendentemente dagli altri, eventualmente coordinandosi con altre SPE per porre in atto lo stream processing.
Ogni SPE č costituita da una unitŕ di calcolo vettoriale (detta SPU) , una memoria SRAM ad alta velocitŕ (256KB nella prima implementazione) ed un Memory Flow Controller per il trasferimento di dati all’esterno della SPE; l’architettura prevede anche una cache di primo livello (SL1), ma nella prima implementazione non č stata realizzata.
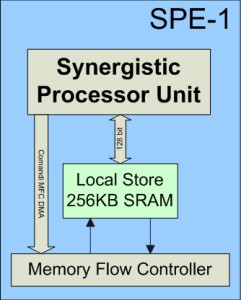 | | Diagramma a blocchi di una SPE |
Esse rappresentano l’anello di congiunzione tra gli ASIC altamente specializzati (ad esempio i chip grafici) ed i processori general purpose; le caratteristiche definite in fase di progettazione le rendono particolarmente efficienti per i seguenti compiti:
-vertex processing e rendering 3D
-codifica, decodifica, transcodifica di flussi multimediali
-simulazioni fisiche in tempo reale
Queste applicazioni tipiche richiedono una grande quantitŕ di calcoli in virgola mobile, tuttavia, siccome č richiesto che questi calcoli vengano eseguiti in real time e non č necessaria una grande precisione, si č optato per un’architettura ottimizzata per numeri in virgola mobile a singola precisione (32-bit). E’ comunque possibile utilizzare valori a doppia precisione, anche se le prestazioni offerte sono di circa un ordine di grandezza inferiore (probabilmente su prossime versioni del processore verrŕ integrato il supporto nativo alla doppia precisione). Tipicamente un Cell con 8 SPE a 4GHz č capace di una potenza di calcolo di 256 gigaflops a singola precisione e circa 25 gigaflops a doppia precisione. Per le applicazioni hard real-time sono disponibili anche apposite funzioni di controllo sul tempo di esecuzione.
Sempre al fine di semplificare al massimo il design, le unitŕ di calcolo in virgola mobile non rispettano pienamente lo standard IEEE 754, infatti č completamente escluso il supporto ai numeri denormalizzati: nell’utilizzo tipico sarebbero del tutto inutili, visto che in genere le applicazioni non richiedono nemmeno la doppia precisione. Quindi nel caso in cui il risultato di una operazione sia al di sotto del minimo valore rappresentabile, questo verrŕ semplicemente posto a 0 e verrŕ segnalato l’underflow nell’apposito registro FPSCR.
Una SPE č dotata di 128 registri da 128-bit per operandi vettoriali, ogni registro puň memorizzare all’interno di ciascun registro uno dei seguenti vettori:
-vettore con 16 componenti interi da 8-bit (16x8-bit)
-vettore con 8 componenti interi da 16-bit (8x16-bit)
-vettore con 4 componenti interi da 32-bit (4x32-bit)
-vettore con 4 componenti in virgola mobile a singola precisione (4x32-bit)
-vettore con 2 componenti in virgola mobile a doppia precisione (2x64-bit)
Le unitŕ di calcolo vettoriale (SIMD) sono in grado di eseguire elaborare tutti questi tipi di vettore; sono presenti 4 unitŕ di calcolo in virgola mobile a singola precisione e 4 unitŕ di calcolo interi.
Per il corretto funzionamento della SPU sono presenti 3 registri interni a 32-bit:
-Run Control Register
-Status Register
-Next Program Counter Register
Il Run Control Register serve per avviare o fermare l’esecuzione di istruzioni, svolge quindi un compito fondamentale nel colloquio tra PPE ed SPE per lo svolgimento delle funzioni di controllo; interessante segnalare la possibilitŕ di esecuzione in modalitŕ “isolata”, che approfondiremo piů avanti.
La funzione di controllo svolta dal kernel del sistema operativo sulle SPE attraverso il PPE va quindi ottimizzata per ottenere il massimo da questa architettura; il classico paradigma della gestione del multitasking attraverso time sharing e scheduling preemptive sebbene sia perfettamente applicabile, č sconsigliato dai progettisti in quanto su una architettura di questo tipo il context switch č particolarmente oneroso e poco efficiente, dovendo salvare (e ripristinare) non solo i 128 registri da 128-bit, ma anche tutti i 256KB della Local Store e le code di comandi dell’MFC. Del resto al programmatore (ed ancor di piů al programmatore del kernel) č richiesta una forte “vicinanza” all’architettura, per cui se il software ed il sistema operativo verranno sviluppati con criterio, il numero di processi in “competizione” per l’accesso alla stessa SPE dovrŕ essere ridotto al minimo, il che non dovrebbe essere difficile visto che ci sono 8 SPE a disposizione.
Lo Status Register indica invece lo stato della SPU, cioč in quale modalitŕ operativa si trova e se sono state eseguite operazioni non valide. E’ importante sottolineare che lo Status Register non mantiene alcuna informazione su stato utente o stato supervisore, in effetti le SPE non fanno alcuna differenza tra le due modalitŕ, ed č per questo che l’accesso in memoria č subordinato allo stato del PPE, inoltre essendo dotate di un set di istruzioni diverso, non sono previste istruzioni privilegiate.
Lo storage model č uno degli aspetti piů interessanti di tutto il Cell, abbiamo infatti i seguenti modelli:
-virtual storage model della PPE
-local storage model della SPE
Il virtual storage model della PPE permette di creare piů “viste” dello spazio di indirizzamento reale (a 64-bit) della memoria di sistema, nonché di proteggere le aree sensibili per il corretto funzionamento del sistema, mentre il local storage model definisce per ogni SPE le modalitŕ di accesso alla propria Local Store. Una SPU puň accedere direttamente alla propria Local Store, o richiedere di accedere alla memoria di sistema inviando una apposita richiesta (detto comando DMA) al proprio MFC, il quale tradurrŕ l’indirizzo virtuale in indirizzo effettivo (tramite una MMU dedicata) ed invierŕ la richiesta al memory controller di sistema, il quale sarŕ comunque subordinato alle eventuali restrizioni imposte dal PPE.
La Local Store di ogni SPE ha inoltre un “alias” nella memoria di sistema (utilizza un approccio Memory Mapped I/O), per cui altre SPE possono referenziare la memoria locale di un’altra SPE per prelevare dati (funzionalitŕ indispensabile per lo stream processing), e difatti ogni MFC gestisce due code di comandi, una proveniente dalla propria SPU ed una proveniente dall’”esterno”.
Vale la pena di spendere qualche parola in piů sulla Local Store delle SPE, essa infatti sebbene per dimensioni e tecnologia realizzativa (256KB SRAM) sia molto simile ad una cache, non č una cache.
Il funzionamento di una cache č completamente automatizzato e “trasparente” al software, appositi circuiti di controllo decidono quali dati tenere “vicino” alle unitŕ di esecuzione e quali riportare in memoria quando risultano non aggiornati o non piů utilizzati, inoltre ormai tutti i processori utilizzano unitŕ di data prefetching per caricare preventivamente in cache i dati che verranno richiesti con maggiore probabilitŕ nel futuro prossimo dell’elaborazione.
Questo approccio ha portato enormi benefici in termini di prestazioni ai moderni processori, tuttavia č costato molto in termini di logica di controllo da integrare ed in ogni caso consente di memorizzare solo pochi blocchi di memoria nella cache (limitazioni di poco conto rispetto ai benefici che portano ai processori general purpose).
Per le applicazioni multimediali (ed in particolare per il Cell) questo approccio non si č rivelato il migliore; i progettisti hanno infatti preferito integrare solo un certo quantitativo di SRAM in ogni SPE, lasciando al programmatore (o al compilatore) il compito di gestirla come meglio crede. In questo modo il design risulta molto piů semplice, eliminando in tronco tutta la logica di controllo necessaria per una cache, e consentendo per di piů al programmatore di utilizzare potenzialmente tutta la SRAM a disposizione con grandi blocchi di dati “utili”. Questo aspetto sebbene richieda un maggiore impegno di programmazione, puň assicurare enormi benefici nell’elaborazione multimediale (ad esempio la decodifica video) durante la quale si opera con grandi quantitŕ di dati.
Un ulteriore oggetto di interesse č una particolare modalitŕ operativa, detta modalitŕ isolata, durante la quale una SPE esegue i propri compiti e puň fornire dati all’esterno, ma i suoi registri e la propria memoria non possono essere in nessun caso visti dall’esterno, nemmeno dal supervisore del sistema. Il passaggio alla modalitŕ isolata (ed il ripristino della modalitŕ “normale”) avviene tramite apposite istruzioni.
Questa funzionalitŕ potrebbe servire per codificare in modo sicuro i dati, tuttavia lo scopo principale per il quale č stata progettata č senza ombra di dubbio l’implementazione di sistemi di protezione dei contenuti (DRM – Digital Rights Management); del resto a guardare le prime implementazioni (PlayStation 3, sistemi HDTV, etc.) la protezione dei contenuti sarŕ un aspetto cruciale.
 | | La tv a retroproiezione di Toshiba |
In conclusione quindi se opportunamente programmate le SPE possono offrire prestazioni di rilievo in ambito multimediale (e piů in generale in ambito compute-intensive); ciň richiederŕ un maggiore sforzo per la progettazione del software, sono tuttavia giŕ disponibili da parte di IBM compilatori e librerie di funzioni per linguaggi ad alto livello che consentono di sfruttare in modo tutto sommato semplice le SPE.
|
Vuoi segnalarci una tua notizia? Clicca qui!
| | | Comments | | | | Annunci | | | Attualitŕ | | Fujitsu presenta la soluzione e roadmap Mobile WiMAX System-on-chip | | Nuovo masterizzatore DVD esterno Sony DRX-820UL | | Nokia 770 Internet Tablet e Google Talk insieme | | Core 2 Duo, gioco di parole per i nuovi processori Intel | | Recensione Crucial Gizmo! Overdrive 1GB online | | LCD con tempo di risposta di 2ms da Acer | | ATi ha acquisito la finlandese BitBoys | | AMD ritira 3000 CPU Opteron difettose | | Intel punta decisa verso i 32 nanometri | | Intel vPro: nuova piattaforma per PC aziendali | | Prove | | Crucial Gizmo! Overdrive 1GB: capacitŕ e prestazioni | | Crucial Gizmo!: 1GB per foto, musica e pinguini | | Raffreddamento a liquido: quando il gioco si fa duro | | Sapphire Radeon X1300: alta definizione per tutti | | Enermax Liberty 500W: la libertŕ fatta alimentatore | | Genius Ergo 300: mouse piccolo ma non troppo | | Royaltek GPS RBT 2001 | | Crucial Ballistix Tracer DDR500: semplicemente estreme | | HP Business Desktop dx5150: potenza per ufficio | | Dal Radeon X600 all'X800: generazioni a confronto in casa Sapphire | |
|





